PDFminer.six を 使ってみる!
➀ pdf2txt.py の場所探し
pdfminer.six を 実行する(使う 動かす)には pdf2txt.py というデータが必要です。実行するには、データがある場所まで移動していき実行するか、そのデータを自分で移動させ実行します。(今回は場所を移動させ実行しました)とにかく、場所を知る必要があるので、まず場所を探してみましょう。

②pdf2txt.py の場所まで行き、コピーする

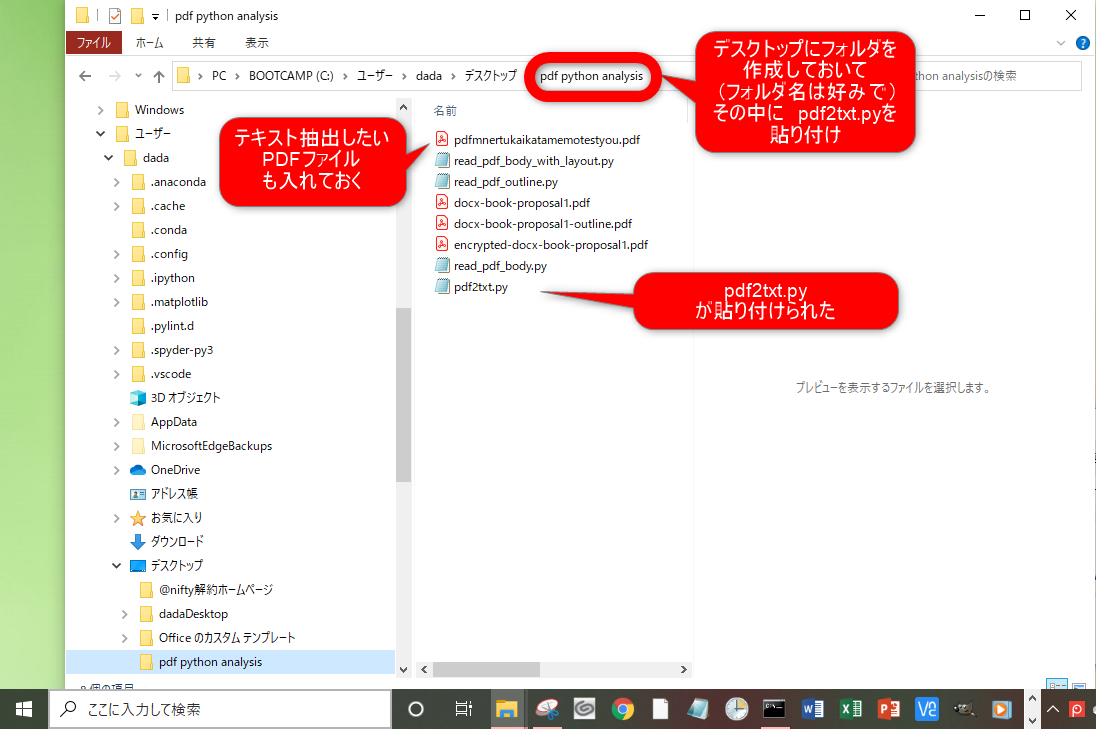
③デスクトップにフォルダを作る(フォルダ名は好みで)
④作成したフォルダ内にpdf2txt.pyを貼り付ける
⑤テキスト抽出したいpdfファイルもフォルダに入れておく
⑥コマンドプロンプトを起動(1,2,3の順にクリックする)

⑦コマンドプロンプトの画面 ( > の右側から入力していく)
⑧cd pdf2txt.pyの場所名 を入力しenterキーを押す
⑨python pdf2txt.py pdf名 を入力しenterキーを押す
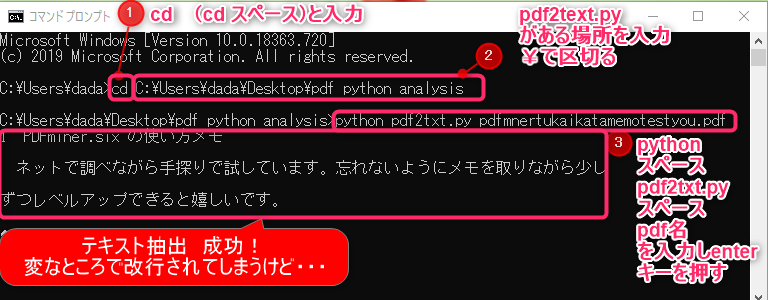
テキスト抽出成功!
変なところで改行されてしまうけれど・・・
※使用した自作pdf 比較してみてください。


コメント