PDFからテキストを抽出したい!
仕事でPDFを見ながら企画書等を作成するとき
「コピペしたいなあ」とか
「見出しの一覧を作成したいなあ」とは
そんなことを思うことがあるのです。
これが、結構地道な作業でくたびれる・・・
そこで、pythonを使って少しでも作業を少なくできないか、
取り組んでみました。
PDF.miner.sixをインストールする!
➀コマンドプロンプトを起動
②python -m python pip upgrade を入力し実行(enterキー)する
※python -m 付け足さないと私の場合は警告が出ました。

久しぶりにpythonを起動 pipバージョンアップが必要!
pipとは、サードパーティが配布しているパッケージをインストールするときに使うコマンドです。pipにもバージョンがあってバージョンのアップグレードが必要です。
python pip upgrade
を入力して実行(enterキー)しましたが、警告が出ました。
python -m を前に入力して実行する必要があるようです。
windowsにpythonを直でインストールしたのではPATH(通り道?)が通らないみたいです。python -m をつけるとPATHを通してい
なくても大丈夫なんだとか・・・
python -m python pip upgrade
入力実行で無事pipのupgradeが成功しました。

もう一度 python -m pip install pdfminer.six を実行しましたが
もうインストールできているよ みたいな メッセージがでています。
これでインストールができたようです。
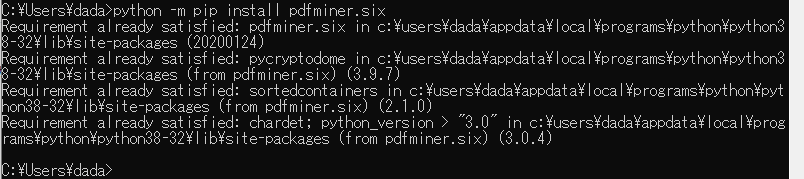
成功!だと思います・・・

コメント